引言
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。
我们可以想,数组作为一个连续的储存空间,通过下标就可以很容易的访问到元素内容,可是进行插入删除操作的复杂度就很高了.而链表以其独特的物理存储结构,正好利于插入删除,而访问却差与数组.
那我们可不可以将这两种数据结构结合起来,取其优点,正好,哈希表就可以完成这样的功能.
比如我们有好多个球.我们将不同颜色的分组放入不同的桶,同一种的元素放入同一个桶中,我们再进行插入删除的时候找桶,然后在桶中做操作就好了.
通过上述的简单分析我们可以发现,hash表的出现就是为了解决单一的数组或单一的链表在查询或插入删除上都有各自的短板,而开链式hash表就是为了将两者的优势结合起来,这样就可以实现更高的查询和删除、添加的效率。
也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
这个映射函数叫做散列函数,存放记录的数组叫做散列表。
例如:给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
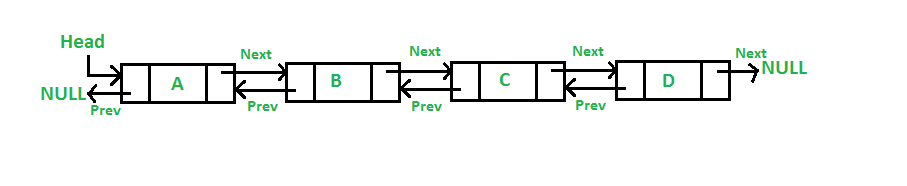
像上图这样,就是一个常见的哈系表.数组中的每一个元素都指向一个链表,这种允许多个关键码值散列到一个数组槽中的hash表叫做开链式哈希表。给定任意一个元素,我们都可以通过数组下标快速定位,然后在其对应的链表里也不用遍历太长,就可以得到元素,并且便于插入删除.

一.哈希表
哈希表就是一种以 键-值(key-indexed) 存储数据的结构,我们只要输入待查找的值即key,即可查找到其对应的值。
哈希的思路很简单,如果所有的键都是整数,那么就可以使用一个简单的无序数组来实现:将键作为索引,值即为其对应的值,这样就可以快速访问任意键的值。这是对于简单的键的情况,我们将其扩展到可以处理更加复杂的类型的键。
hash表也有一定的隐患,那就是如果运气很不好,所有的关键值码全部都散列到了一个槽内,那么原本的hash表则又退化为了单链表, 
二.哈希表的数据结构定义及接口
hash函数的数据结构定义及接口声明
1 | |
三.哈希表的接口实现
我们仍旧通过以前实现的dlist进行封装
详见数据结构4.进一步封装的双向链表
目录结构
1
2
3
4
5
6
7
8
9
10
11.
├── dlist.c
├── dlist.h
├── hash.c
├── hash.h
├── iterator.h
├── main.c
├── tools.c
└── tools.h
0 directories, 8 fileshash.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "hash.h"
#include "dlist.h"
#include "tools.h"
//hash表的初始化
Hash *init_hash(int b_size, Hash_func hash_func)
{
if(b_size < 0)
{
return NULL;
}
Hash *hash = (Hash *)Malloc(sizeof(Hash));
bzero(hash, sizeof(Hash));
hash->element_count = 0;
//hash初始元素个数为0
hash->bucket_size = b_size;
//指定了初始化桶的个数
hash->table = (Dlist **)Malloc(sizeof(Dlist *) * b_size);
bzero(hash->table, sizeof(Dlist *)* b_size);
//先为各个桶申请地址,但不初始化;
//后面进行插入时再初始化
hash->hash_func = hash_func;
hash->hash_match = NULL;
hash->hash_free = NULL;
return hash;
}
//2.哈希表的销毁
void destroy_hash(Hash **hash) //哈希表的销毁
{
int i = 0;
int bucket_size = 0;
Hash *p_hash = NULL;
// 销毁步骤:
//1. 销毁每一个桶(双端链表);
//2. 销毁table;
//3. 销毁hash;
if(hash == NULL || *hash == NULL){
return ;
}
p_hash = *hash;
bucket_size = p_hash->bucket_size;
for(i = 0; i < bucket_size; ++i){
destroy_dlist(&(p_hash->table[i]));
}
free(p_hash->table);
free(p_hash);
p_hash = NULL;
}
//hash表寻找元素
Boolean hash_search(Hash *hash, const void *value)
{
if(NULL == hash || NULL == value)
{
return FALSE;
}
int i = 0;
int bucket = 0;
Dlist_node *p_node = NULL;
//1.通过value和hash_func可以计算value元素应该在哪个桶里
bucket = hash->hash_func(value) % hash->bucket_size;
//2.是否存在桶?不存在则返回FALSE
if(hash->table[bucket] == NULL)
{
return FALSE;
}
//3.如果存在这样的桶,则遍历链表查找
for(p_node = hash->table[bucket]->head;
p_node ; p_node = p_node->next)
{
//如果用户设置了匹配方案,则按该方法判断,
if( hash->hash_match != NULL )
{
if(hash->hash_match(p_node->data, value) == TRUE)
{
return TRUE;
}
}
else//若用户未设置匹配方法,则直接比较
{
if(p_node->data == value)
{
return TRUE;
}
}
}
return FALSE;
}
//hash表插入元素
Boolean hash_insert(Hash *hash, const void *value)
{
//如果hash表不存在或元素已经存在于桶中,则不进行插入
if(NULL == hash || NULL == value || TRUE == hash_search(hash, value))
{
return FALSE;
}
int i = 0;
int bucket = 0;
//判断元素所在桶的下标
bucket = hash->hash_func(value) % hash->bucket_size;
//插入操作时,如果桶不存在,则初始化这个桶
if(NULL== hash->table[bucket] )
{
hash->table[bucket] = init_dlist();
}
//通过尾插将元素插入当前桶
push_back(hash->table[bucket], (void *)value);
hash->element_count ++;
return TRUE;
}
//hash表移除元素
Boolean hash_remove(Hash *hash, const void *value)
{
//如果hash表不存在或元素不存在于桶中,则不进行删除
if(NULL == hash || NULL == value || FALSE == hash_search(hash, value))
{
return FALSE;
}
int i = 0;
int bucket = 0;
Dlist_node *p_node = NULL;
//判断元素所在桶的下标
bucket = (*(int *)value) % hash->bucket_size;
//遍历链表查找
for(p_node = hash->table[bucket]->head;
p_node ; p_node = p_node->next)
{
//如果用户设置了匹配方案,则按该方法判断,
if( hash->hash_match != NULL )
{
if(hash->hash_match(p_node->data, value) == TRUE)
{
//先寻找,再删除
remove_dlist_node(hash->table[bucket], p_node);
hash->element_count--;
return TRUE;
}
}
else
{
//若用户未设置匹配方法,则直接比较
if(p_node->data == value)
{
remove_dlist_node(hash->table[bucket], p_node);
hash->element_count--;
return TRUE;
}
}
}
return FALSE;
}
//hash表元素个数
int get_hash_element_count(Hash *hash)
{
if(NULL == hash)
{
return -1;
}
return hash->element_count;
}
//hash表的显示
void show_hash_table(Hash *hash)
{
int i = 0;
int size = hash->bucket_size;
if(NULL == hash || hash->element_count == ZERO)
{
printf("The hash table is NULL.\n");
return;
}
for(i = 0; i < size; i++)
{
if(hash->table[i] != NULL)
{
printf("table[%d]: ", i);
show_dlist((hash->table[i]), print_int);
}
}
}
int int_hash_func(const void *key)
{
return *(int *)key;
}
四.代码功能测试
- main.c
1 | |
1 | |
总结
我们可以看到,我们随机生成了100个数字,然后通过hash函数将其分布在不同的桶中.而且每个桶中的元素不同长度.如果分布的越均匀,则让后期的查询效率越高,所以我们一定要设计好hash函数,让关键值能够均匀分布.
哈希查找第一步就是使用哈希函数将键映射成索引。这种映射函数就是哈希函数。如果我们有一个保存0-M数组,那么我们就需要一个能够将任意键转换为该数组范围内的索引(0~M-1)的哈希函数。哈希函数需要易于计算并且能够均匀分布所有键。
比如举个简单的例子,使用手机号码后三位就比前三位作为key更好,因为前三位手机号码的重复率很高。再比如使用身份证号码出生年月位数要比使用前几位数要更好。